

Property Graph Index
![]()
In this notebook, we demonstrate some basic usage of the PropertyGraphIndex in LlamaIndex.
The property graph index here will take unstructured documents, extract a property graph from it, and provide various methods to query that graph.
%pip install llama-indeximport os
os.environ["OPENAI_API_KEY"] = "sk-proj-..."!mkdir -p 'data/paul_graham/'!wget 'https://raw.githubusercontent.com/run-llama/llama_index/main/docs/examples/data/paul_graham/paul_graham_essay.txt' -O 'data/paul_graham/paul_graham_essay.txt'import nest_asyncio
nest_asyncio.apply()from llama_index.core import SimpleDirectoryReader
documents = SimpleDirectoryReader("./data/paul_graham/").load_data()Construction
Section titled “Construction”from llama_index.core import PropertyGraphIndexfrom llama_index.embeddings.openai import OpenAIEmbeddingfrom llama_index.llms.openai import OpenAI
index = PropertyGraphIndex.from_documents( documents, llm=OpenAI(model="gpt-3.5-turbo", temperature=0.3), embed_model=OpenAIEmbedding(model_name="text-embedding-3-small"), show_progress=True,)/Users/loganmarkewich/Library/Caches/pypoetry/virtualenvs/llama-index-bXUwlEfH-py3.11/lib/python3.11/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html from .autonotebook import tqdm as notebook_tqdmParsing nodes: 100%|██████████| 1/1 [00:00<00:00, 25.46it/s]Extracting paths from text: 100%|██████████| 22/22 [00:12<00:00, 1.72it/s]Extracting implicit paths: 100%|██████████| 22/22 [00:00<00:00, 36186.15it/s]Generating embeddings: 100%|██████████| 1/1 [00:00<00:00, 1.14it/s]Generating embeddings: 100%|██████████| 5/5 [00:00<00:00, 5.43it/s]So lets recap what exactly just happened
PropertyGraphIndex.from_documents()- we loaded documents into an indexParsing nodes- the index parsed the documents into nodesExtracting paths from text- the nodes were passed to an LLM, and the LLM was prompted to generate knowledge graph triples (i.e. paths)Extracting implicit paths- eachnode.relationshipsproperty was used to infer implicit pathsGenerating embeddings- embeddings were generated for each text node and graph node (hence this happens twice)
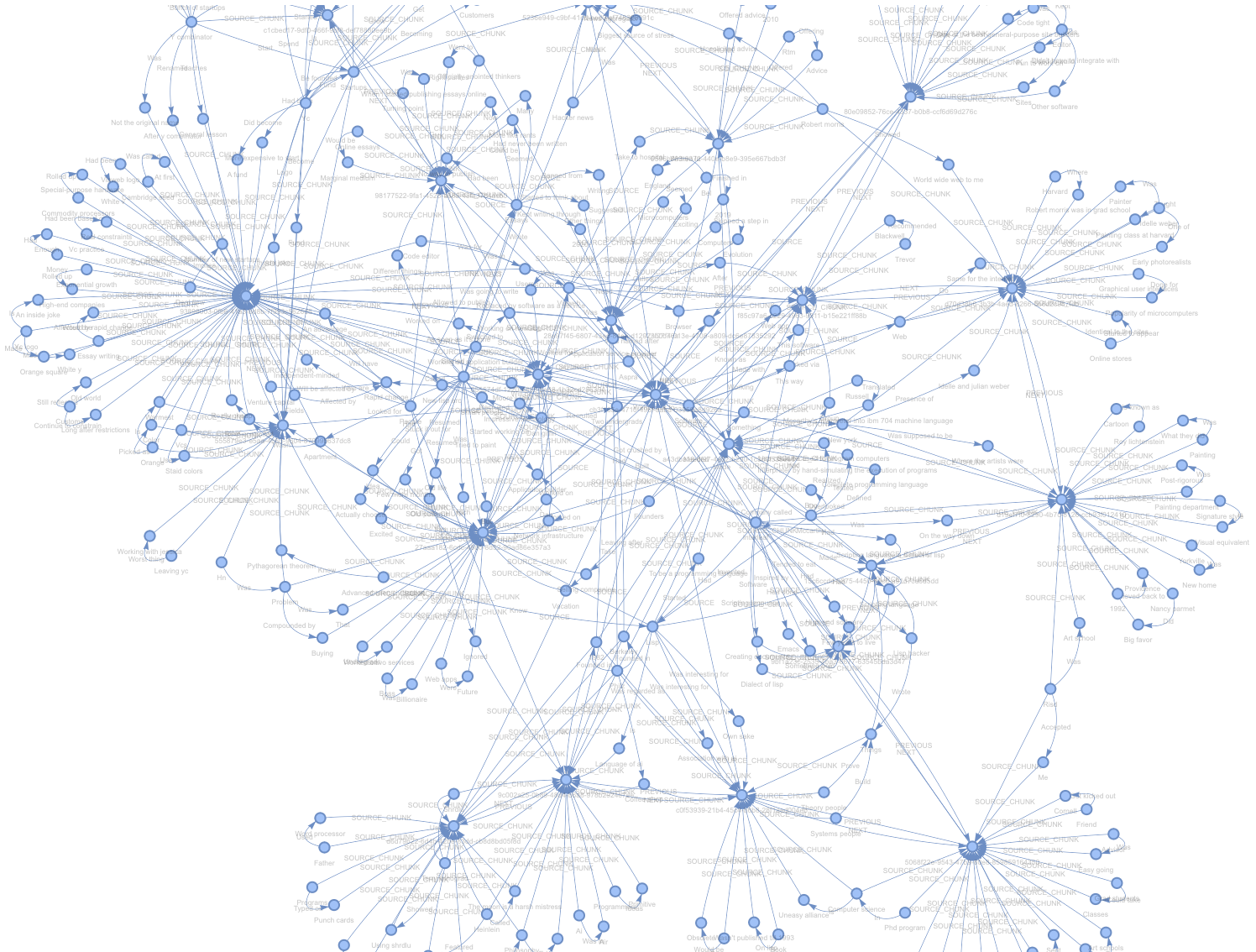
Lets explore what we created! For debugging purposes, the default SimplePropertyGraphStore includes a helper to save a networkx representation of the graph to an html file.
index.property_graph_store.save_networkx_graph(name="./kg.html")Opening the html in a browser, we can see our graph!
If you zoom in, each “dense” node with many connections is actually the source chunk, with extracted entities and relations branching off from there.
Customizing Low-Level Construction
Section titled “Customizing Low-Level Construction”If we wanted, we can do the same ingestion using the low-level API, leverage kg_extractors.
from llama_index.core.indices.property_graph import ( ImplicitPathExtractor, SimpleLLMPathExtractor,)
index = PropertyGraphIndex.from_documents( documents, embed_model=OpenAIEmbedding(model_name="text-embedding-3-small"), kg_extractors=[ ImplicitPathExtractor(), SimpleLLMPathExtractor( llm=OpenAI(model="gpt-3.5-turbo", temperature=0.3), num_workers=4, max_paths_per_chunk=10, ), ], show_progress=True,)For a full guide on all extractors, see the detailed usage page.
Querying
Section titled “Querying”Querying a property graph index typically consists of using one or more sub-retrievers and combining results.
Graph retrieval can be thought of
- selecting node(s)
- traversing from those nodes
By default, two types of retrieval are used in unison
- synoynm/keyword expansion - use the LLM to generate synonyms and keywords from the query
- vector retrieval - use embeddings to find nodes in your graph
Once nodes are found, you can either
- return the paths adjacent to the selected nodes (i.e. triples)
- return the paths + the original source text of the chunk (if available)
retriever = index.as_retriever( include_text=False, # include source text, default True)
nodes = retriever.retrieve("What happened at Interleaf and Viaweb?")
for node in nodes: print(node.text)Interleaf -> Was -> On the way downViaweb -> Had -> Code editorInterleaf -> Built -> Impressive technologyInterleaf -> Added -> Scripting languageInterleaf -> Made -> Scripting languageViaweb -> Suggested -> Take to hospitalInterleaf -> Had done -> Something boldViaweb -> Called -> AfterInterleaf -> Made -> Dialect of lispInterleaf -> Got crushed by -> Moore's lawDan giffin -> Worked for -> ViawebInterleaf -> Had -> Smart peopleInterleaf -> Had -> Few years to liveInterleaf -> Made -> SoftwareInterleaf -> Made -> Software for creating documentsPaul graham -> Started -> ViawebScripting language -> Was -> Dialect of lispScripting language -> Is -> Dialect of lispSoftware -> Will be affected by -> Rapid changeCode editor -> Was -> In viawebSoftware -> Worked via -> WebPrograms -> Typed on -> Punch cardsComputers -> Skipped -> StepIdea -> Was clear from -> ExperienceApartment -> Wasn't -> Rent-controlledquery_engine = index.as_query_engine( include_text=True,)
response = query_engine.query("What happened at Interleaf and Viaweb?")
print(str(response))Interleaf had smart people and built impressive technology, including adding a scripting language that was a dialect of Lisp. However, despite their efforts, they were eventually impacted by Moore's Law and faced challenges. Viaweb, on the other hand, was started by Paul Graham and had a code editor where users could define their own page styles using Lisp expressions. Viaweb also suggested taking someone to the hospital and called something "After."For full details on customizing retrieval and querying, see the docs page.
Storage
Section titled “Storage”By default, storage happens using our simple in-memory abstractions - SimpleVectorStore for embeddings and SimplePropertyGraphStore for the property graph.
We can save and load these to/from disk.
index.storage_context.persist(persist_dir="./storage")
from llama_index.core import StorageContext, load_index_from_storage
index = load_index_from_storage( StorageContext.from_defaults(persist_dir="./storage"))Vector Stores
Section titled “Vector Stores”While some graph databases support vectors (like Neo4j), you can still specify the vector store to use on top of your graph for cases where its not supported, or cases where you want to override.
Below we will combine ChromaVectorStore with the default SimplePropertyGraphStore.
%pip install llama-index-vector-stores-chromafrom llama_index.core.graph_stores import SimplePropertyGraphStorefrom llama_index.vector_stores.chroma import ChromaVectorStoreimport chromadb
client = chromadb.PersistentClient("./chroma_db")collection = client.get_or_create_collection("my_graph_vector_db")
index = PropertyGraphIndex.from_documents( documents, embed_model=OpenAIEmbedding(model_name="text-embedding-3-small"), graph_store=SimplePropertyGraphStore(), vector_store=ChromaVectorStore(collection=collection), show_progress=True,)
index.storage_context.persist(persist_dir="./storage")Then to load:
index = PropertyGraphIndex.from_existing( SimplePropertyGraphStore.from_persist_dir("./storage"), vector_store=ChromaVectorStore(chroma_collection=collection), llm=OpenAI(model="gpt-3.5-turbo", temperature=0.3),)This looks slightly different than purely using the storage context, but the syntax is more concise now that we’ve started to mix things together.