

Overview of Parse
Parse is an agentic document parser built for LLM pipelines—layout-aware OCR that turns PDFs, scans, tables, and charts into clean markdown, text, or JSON.
Parse is an agentic document parser built for LLM pipelines. It reads tables, charts, scanned pages, and 130+ file types with layout-aware accuracy that generic OCR and PDF-to-text tools can’t match—and hands you clean markdown, text, or JSON ready to feed straight into your model.
What teams build with Parse
Section titled “What teams build with Parse”- Financial RAG — parse tables, footnotes, and charts in 10-Ks, earnings reports, and investor decks without losing cell structure.
- Compliance workflows — turn filings, transcripts, and policy documents into clean text for automated review and flagging.
- Contract intelligence — preserve section hierarchy and extract clauses with custom prompts.
- Medical & insurance records — parse scanned claims, lab reports, and intake forms with reliable field extraction.
- Operational documents — extract fields from tickets, orders, invoices, and forms for downstream workflows.
- Scientific & technical literature — handle multi-column layouts, equations, figures, and references from research papers and manuals.
Why Parse
Section titled “Why Parse”High-quality document parsing is one of the most overlooked—yet crucial—steps in the LLM stack. Models can only reason with the information you give them, and most real-world documents are hard to interpret out of the box: multi-column layouts, merged table cells, charts embedded as images, handwritten annotations, scanned pages at odd angles.
Most parsers are bounding-box detectors bolted onto an OCR engine. Parse is different. It uses generative models for end-to-end document understanding, so layout, structure, tables, charts, and text all come out of the same reasoning pass—instead of getting stitched back together from dozens of fragile heuristics. That’s why it handles complex real-world documents where traditional parsers break down.
Parse vs. feeding PDFs directly to an LLM
Section titled “Parse vs. feeding PDFs directly to an LLM”For a single short document, passing the raw PDF to a multimodal model often works fine. At scale it breaks down: tables lose structure, scanned pages produce noisy OCR, and token cost scales linearly with raw page content regardless of whether it carried useful signal. Parse does the structural work once, upstream, so downstream models only see clean, layout-aware input.
Your first parse in 5 lines
Section titled “Your first parse in 5 lines”from llama_cloud import LlamaCloud
client = LlamaCloud() # reads LLAMA_CLOUD_API_KEYfile = client.files.create(file="doc.pdf", purpose="parse")result = client.parsing.parse(file_id=file.id, tier="agentic", version="latest")print(result.markdown.pages[0].markdown)Full setup for Python, TypeScript, REST, and the Web UI → Getting Started.
Core Features
Section titled “Core Features”-
Flexible tiers — pick the right cost-to-accuracy tradeoff for every job:
- Agentic Plus — state-of-the-art models for maximum accuracy on the hardest documents.
- Agentic — advanced parsing agents for complex, visually rich files.
- Cost Effective — balanced performance and cost for everyday workloads.
- Fast — lowest-latency, lowest-cost tier for plain-text documents at high volume; returns text and spatial text only (no markdown).
See the full tier comparison →
-
Layout-aware table extraction — accurately recover tables from PDFs, scans, and images with cell structure preserved, so downstream models and spreadsheets get the data right the first time.
-
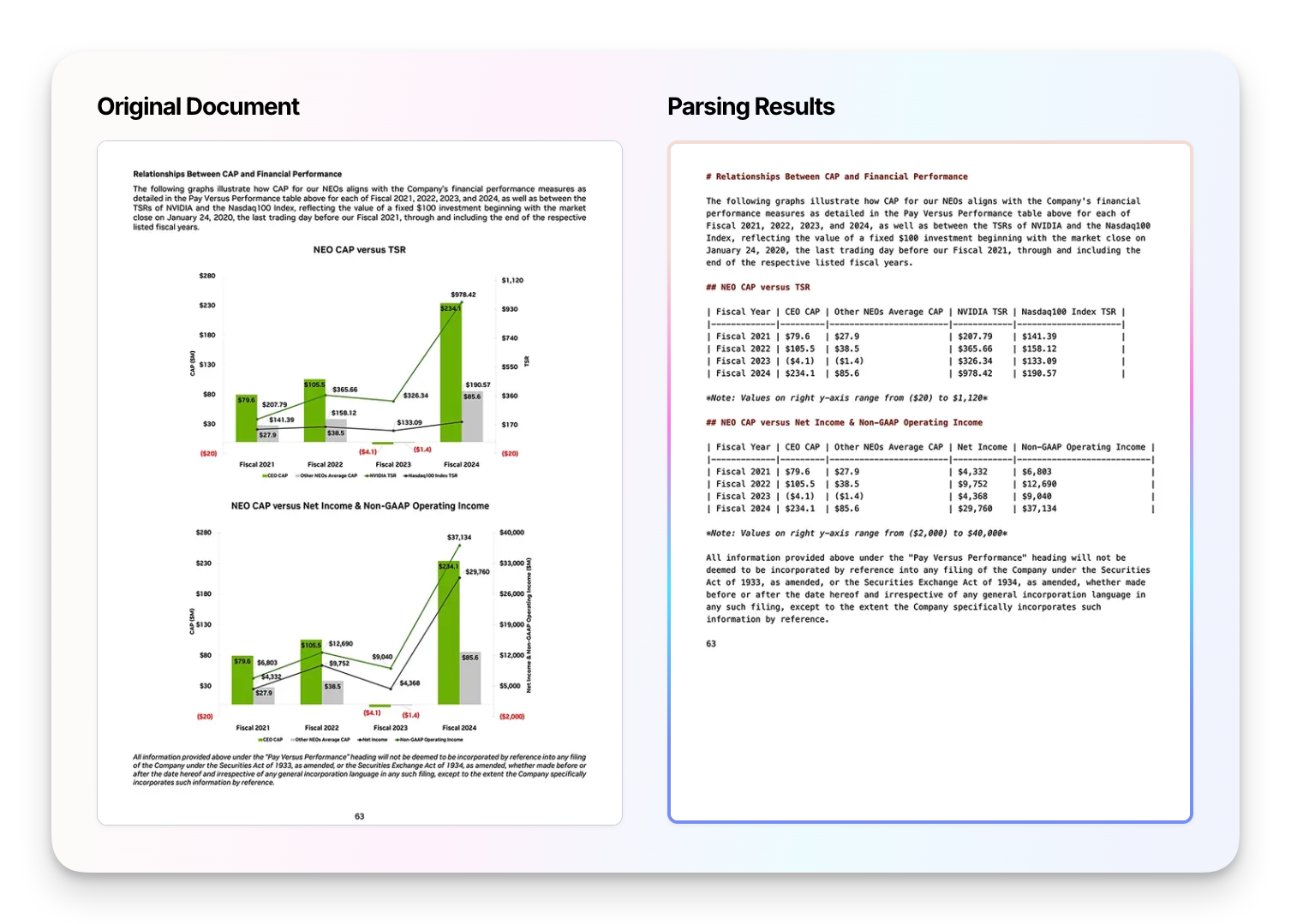
Chart & diagram parsing — extract charts, plots, and diagrams into structured data so LLMs can reason over the numbers, not just the pixels.
-
Custom prompts & output schemas — steer the parser with natural-language instructions or structured output schemas to shape the result to your pipeline.
-
Cost Optimizer — pay premium prices only on the pages that need it. Parse routes each page in your document to the right tier automatically: simple pages go to the cheaper
cost_effectivetier, complex pages (tables, charts, multi-column layouts, diagrams) stay on your premium tier, and both run in parallel so there’s no latency penalty. Learn more → -
130+ file types — PDF, DOCX, PPTX, XLSX, HTML, JPEG, PNG, XML, EPUB, and many more →.
-
Production-ready — automatic caching, webhooks, page-level controls, and versioned tiers you can pin for reproducible output in production.
Workflow
Section titled “Workflow”-
Connect your documents Upload or stream documents via our API, SDKs, or Web UI—with built-in connectors for enterprise data sources.
-
Configure your parsing Pick a tier for a quick start, or define a custom configuration with specific models, output formats, and parsing instructions for your use case.
-
Get clean, structured results Receive parsed output your pipeline can consume directly—see Output Options for the full list.