

Extracting Repeating Entities with Table Row Extaction
This examples demonstrates how to use the PER_TABLE_ROW extraction target to extract structured data from documents containing repeating entities like tables, lists, or catalogs.
Why Use the Tabular Extraction Target?
Section titled “Why Use the Tabular Extraction Target?”PER_DOC (refer to the table below for a quick overview of the different extraction targets) is the default extraction target in LlamaExtract, which looks at the entire document’s context when doing an extraction. When extracting lists of entities, LLM-based extraction has a critical failure mode — it often only extracts the first few tens of entries from a long list. This happens because LLMs have limited attention spans for repetitive data. Document-level extraction doesn’t guarantee exhaustive coverage, and long lists lead to incomplete extractions.
The Solution: PER_TABLE_ROW solves this by processing each entity individually or in smaller batches, ensuring exhaustive extraction of all entries regardless of list length.
Entity-Level Extraction
Section titled “Entity-Level Extraction”When using extraction_target=ExtractTarget.PER_TABLE_ROW, you define a schema for a single entity (e.g., one hospital, one product, one invoice line item), not the full document. LlamaExtract automatically:
- Detects the formatting patterns that distinguish individual entities (table rows, list items, section headers, etc.)
- Applies your schema to each identified entity
- Returns a
list[YourSchema]with one object per entity
This approach is ideal when each entity locally contains all the information needed for your schema.
Choosing the Right Extraction Target
Section titled “Choosing the Right Extraction Target”| Extraction Target | Best For | Returns |
|---|---|---|
PER_DOC | Single-entity documents, summaries, or short lists | One JSON object for entire document |
PER_PAGE | Multi-page documents where each page is independent | One JSON object per page |
PER_TABLE_ROW | Long lists, tables, catalogs with repeating entities | List of JSON objects (one per entity) |
📖 For more details, see the Extraction Target documentation.
pip install llama_cloud>=1.0from llama_cloud import LlamaCloud, AsyncLlamaCloud
client = LlamaCloud(api_key="your_api_key") # Or reads from LLAMA_CLOUD_API_KEY env varnpm install @llamaindex/llama-cloud zodimport LlamaCloud from "@llamaindex/llama-cloud";
const client = new LlamaCloud({ apiKey: "your_api_key", // Or reads from LLAMA_CLOUD_API_KEY env var});pip install llama_cloud_services python-dotenvfrom dotenv import load_dotenvfrom llama_cloud_services import LlamaExtract
# Load environment variables (put LLAMA_CLOUD_API_KEY in your .env file)load_dotenv(override=True)
# Optionally, add your project id/organization idllama_extract = LlamaExtract()Table of Hospitals by County and Insurance Plans
Section titled “Table of Hospitals by County and Insurance Plans”We have a PDF document with a list of hospitals by county and different insurance plans offered by Blue Shield of California.
You can get
BSC-Hospital-List-by-County.pdfhere
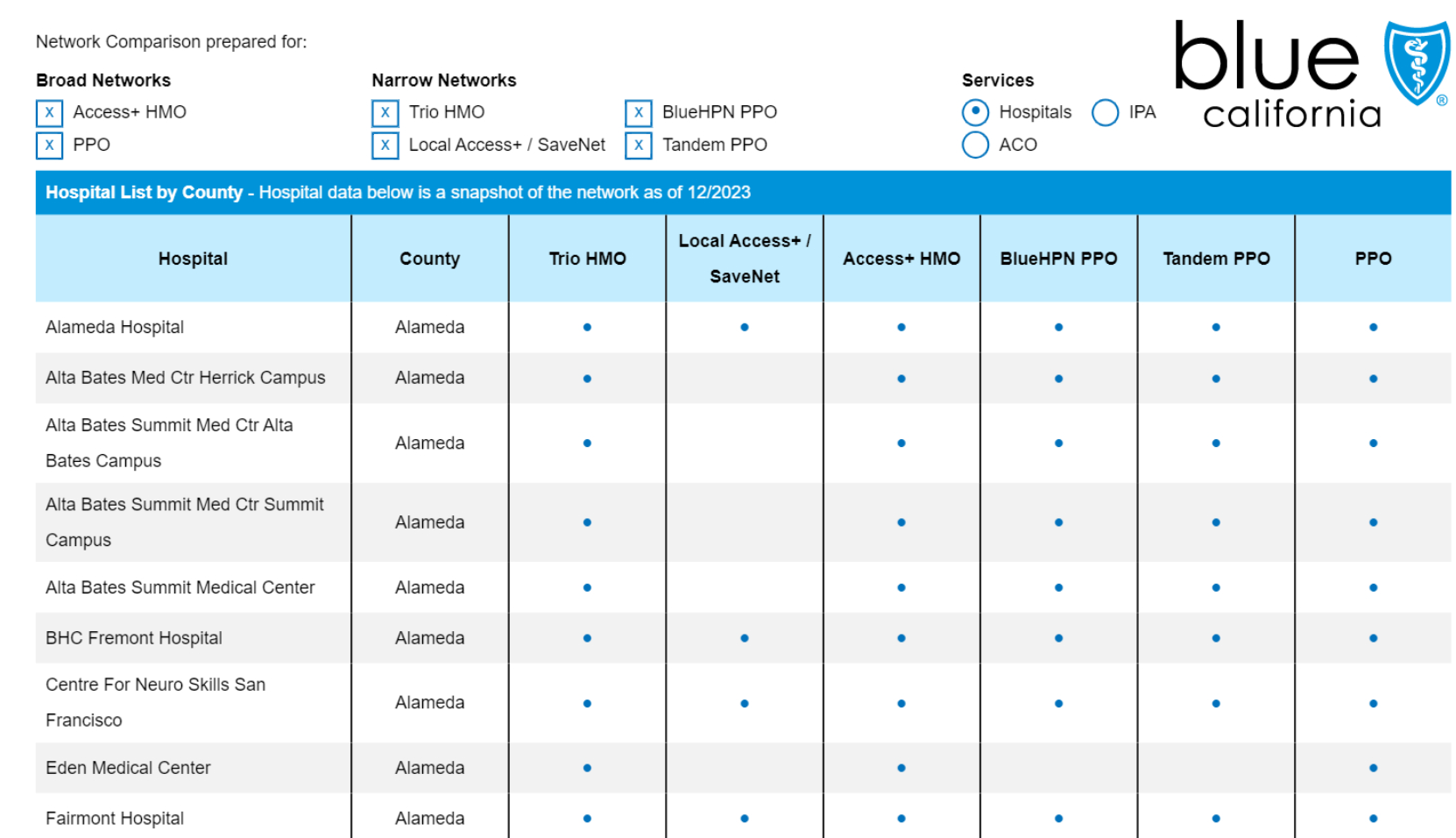
We want to extract each hospital from this table along with a list of applicable insurance plans.
Example 1: Structured Table
Section titled “Example 1: Structured Table”This is an ideal use case for PER_TABLE_ROW extraction:
- Clear structure: The document has explicit table formatting with rows and columns
- Repeating entities: Each row represents one hospital with consistent attributes
- Local information: All data for each hospital (county, name, plans) is contained within its row
Notice that our Hospital schema describes a single hospital, not the full document. LlamaExtract will return a list[Hospital] with one entry per table row.
from pydantic import BaseModel, Field
class Hospital(BaseModel): """List of hospitals by county available for different BSC plans"""
county: str = Field(description="County name") hospital_name: str = Field(description="Name of the hospital") plan_names: list[str] = Field( description="List of plans available at the hospital. One of: Trio HMO, SaveNet, Access+ HMO, BlueHPN PPO, Tandem PPO, PPO" )file_obj = await client.files.create(file="BSC-Hospital-List-by-County.pdf", purpose="extract")file_id = file_obj.id
# Stateless one-shot extractionresult = client.extraction.extract( file_id=file_id, config={ "extraction_mode": "PREMIUM", "extraction_target": "PER_TABLE_ROW", "parse_model": "anthropic-sonnet-4.5", }, data_schema=Hospital.model_json_schema(),)import { z } from "zod";
const HospitalSchema = z.object({ county: z.string().describe("County name"), hospital_name: z.string().describe("Name of the hospital"), plan_names: z .array( z.enum([ "Trio HMO", "SaveNet", "Access+ HMO", "BlueHPN PPO", "Tandem PPO", "PPO", ]) ) .describe( "List of plans available at the hospital. One of: Trio HMO, SaveNet, Access+ HMO, BlueHPN PPO, Tandem PPO, PPO" ),});import fs from "fs";
const fileObj = await client.files.create({ file: fs.createReadStream("BSC-Hospital-List-by-County.pdf"), purpose: "extract",});const fileId = fileObj.id;
// Stateless one-shot extractionconst result = await client.extraction.extract({ file_id: fileId, config: { extraction_mode: "PREMIUM", extraction_target: "PER_TABLE_ROW", parse_model: "anthropic-sonnet-4.5", }, data_schema: z.toJSONSchema(HospitalSchema),});from pydantic import BaseModel, Field
class Hospital(BaseModel): """List of hospitals by county available for different BSC plans"""
county: str = Field(description="County name") hospital_name: str = Field(description="Name of the hospital") plan_names: list[str] = Field( description="List of plans available at the hospital. One of: Trio HMO, SaveNet, Access+ HMO, BlueHPN PPO, Tandem PPO, PPO" )from llama_cloud_services.extract import ExtractConfig, ExtractMode, ExtractTarget
result = await llama_extract.aextract( data_schema=Hospital, files="BSC-Hospital-List-by-County.pdf", config=ExtractConfig( extraction_mode=ExtractMode.PREMIUM, extraction_target=ExtractTarget.PER_TABLE_ROW, parse_model="anthropic-sonnet-4.5", ),)Results
Section titled “Results”If we count the length of extracted hospitals, we see we got all 380 entries!
Printing the first few extracted hospitals:
[{'county': 'Alameda', 'hospital_name': 'Alameda Hospital', 'plan_names': ['Trio HMO', 'SaveNet', 'Access+ HMO', 'BlueHPN PPO', 'Tandem PPO', 'PPO']}, {'county': 'Alameda', 'hospital_name': 'Alta Bates Med Ctr Herrick Campus', 'plan_names': ['Trio HMO', 'Access+ HMO', 'BlueHPN PPO', 'Tandem PPO', 'PPO']}, {'county': 'Alameda', 'hospital_name': 'Alta Bates Summit Med Ctr Alta Bates Campus', 'plan_names': ['Trio HMO', 'Access+ HMO', 'BlueHPN PPO', 'Tandem PPO', 'PPO']}, {'county': 'Alameda', 'hospital_name': 'Alta Bates Summit Med Ctr Summit Campus', 'plan_names': ['Trio HMO', 'Access+ HMO', 'BlueHPN PPO', 'Tandem PPO', 'PPO']}, {'county': 'Alameda', 'hospital_name': 'Alta Bates Summit Medical Center', 'plan_names': ['Trio HMO', 'Access+ HMO', 'BlueHPN PPO', 'Tandem PPO', 'PPO']}, {'county': 'Alameda', 'hospital_name': 'BHC Fremont Hospital', 'plan_names': ['Trio HMO', 'SaveNet', 'Access+ HMO', 'BlueHPN PPO', 'Tandem PPO', 'PPO']}, {'county': 'Alameda', 'hospital_name': 'Centre For Neuro Skills San Francisco', 'plan_names': ['Trio HMO', 'SaveNet', 'Access+ HMO', 'BlueHPN PPO', 'Tandem PPO', 'PPO']}, {'county': 'Alameda', 'hospital_name': 'Eden Medical Center', 'plan_names': ['Trio HMO', 'Access+ HMO', 'PPO']}, {'county': 'Alameda', 'hospital_name': 'Fairmont Hospital', 'plan_names': ['Trio HMO', 'SaveNet', 'Access+ HMO', 'BlueHPN PPO', 'Tandem PPO', 'PPO']}, {'county': 'Alameda', 'hospital_name': 'Highland Hospital', 'plan_names': ['Trio HMO', 'SaveNet', 'Access+ HMO', 'BlueHPN PPO', 'Tandem PPO', 'PPO']}]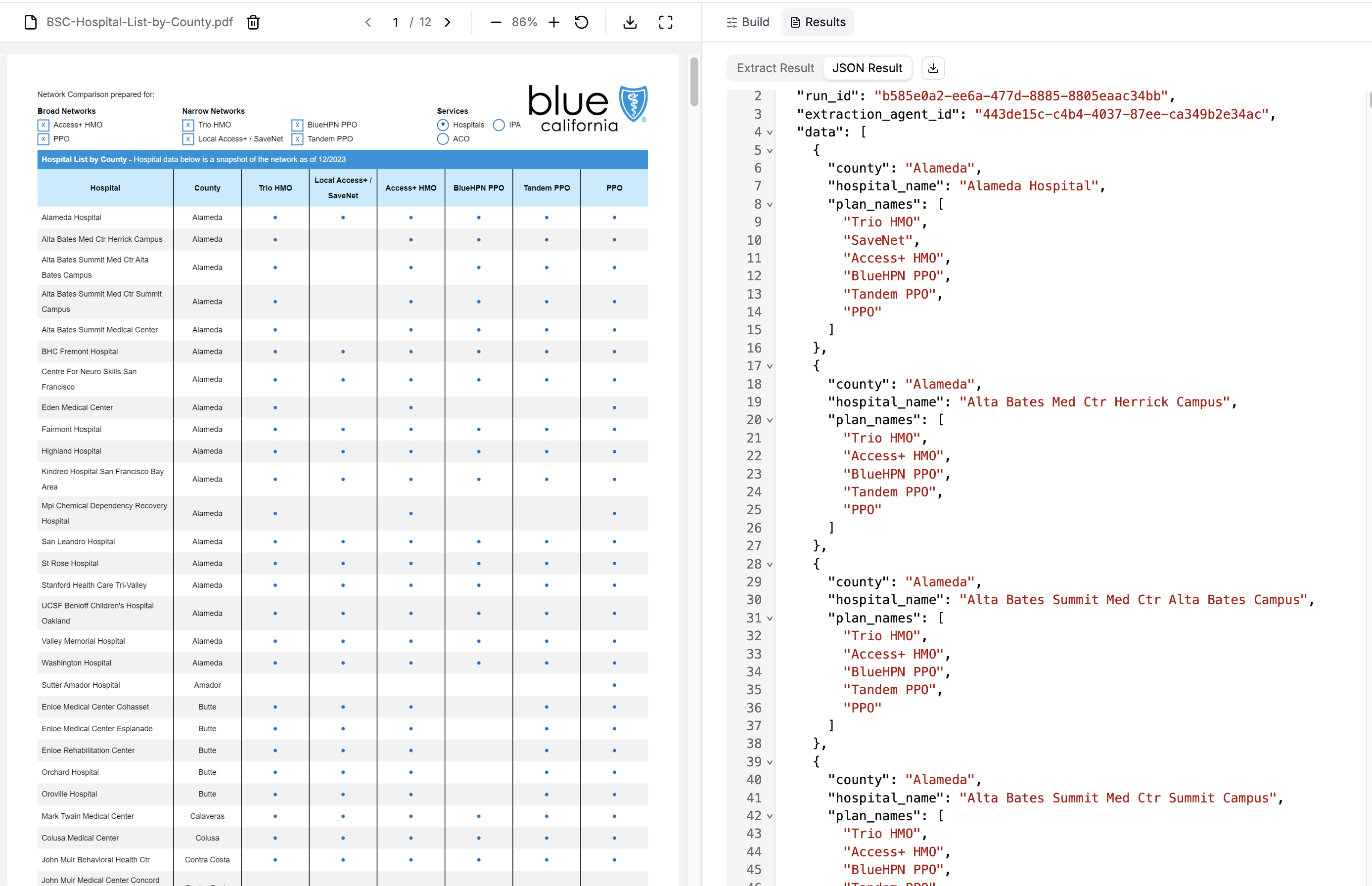
Success! We extracted all 380 hospitals from the multi-page PDF. Each entity was correctly parsed with its county, hospital name, and applicable insurance plans. With PER_DOC, we would likely have only gotten the first 20-30 entries.
Extracting from a Toy Catalog
Section titled “Extracting from a Toy Catalog”Example 2: Semi-Structured List
Section titled “Example 2: Semi-Structured List”The PER_TABLE_ROW extraction target also works well for documents that aren’t explicit tables but have similar properties:
- Ordered listing: The toys are listed sequentially with visual separation (section headers, spacing)
- Repeating pattern: Each toy entry has a consistent structure (code, name, specs, description)
- Local information: All attributes for each toy are grouped together in its entry
Even though this isn’t a traditional table format, each toy entity locally contains all the information needed for our schema. LlamaExtract detects the formatting patterns that distinguish each toy and extracts them as separate entities.

from pydantic import BaseModel, Field
class ToyCatalog(BaseModel): """Product information from a toy catalog."""
section_name: str = Field( description="The name of the toy section (e.g. Table Toys, Active Toys)." ) product_code: str = Field( description="The unique product code for the toy (e.g., GA457)." ) toy_name: str = Field(description="The name of the toy.") age_range: str = Field( description="The recommended age range for the toy (e.g., 6 +, 4 +).", ) player_range: str = Field( description="The number of players the toy is designed for (e.g., 2, 2-4, 1-6).", ) material: str = Field( description="The primary material(s) the toy is made of (e.g., wood, cardboard).", ) description: str = Field( description="A brief description of the toy and its components and dimensions.", )file_obj = await client.files.create(file="Click-BS-Toys-Catalogue-2024.pdf", purpose="extract")file_id = file_obj.id
# Stateless one-shot extractionresult = client.extraction.extract( file_id=file_id, config={ "extraction_mode": "PREMIUM", "extraction_target": "PER_TABLE_ROW", "parse_model": "anthropic-sonnet-4.5", }, data_schema=ToyCatalog.model_json_schema(),)import { z } from "zod";
const ToyCatalogSchema = z.object({ section_name: z .string() .describe("The name of the toy section (e.g. Table Toys, Active Toys)."), product_code: z .string() .describe("The unique product code for the toy (e.g., GA457)."), toy_name: z.string().describe("The name of the toy."), age_range: z .string() .describe("The recommended age range for the toy (e.g., 6 +, 4 +)."), player_range: z .string() .describe( "The number of players the toy is designed for (e.g., 2, 2-4, 1-6)." ), material: z .string() .describe( "The primary material(s) the toy is made of (e.g., wood, cardboard)." ), description: z .string() .describe( "A brief description of the toy and its components and dimensions." ),});import fs from "fs";
const fileObj = await client.files.create({ file: fs.createReadStream("Click-BS-Toys-Catalogue-2024.pdf"), purpose: "extract",});const fileId = fileObj.id;
// Stateless one-shot extractionconst result = await client.extraction.extract({ file_id: fileId, config: { extraction_mode: "PREMIUM", extraction_target: "PER_TABLE_ROW", parse_model: "anthropic-sonnet-4.5", }, data_schema: z.toJSONSchema(ToyCatalogSchema),});from pydantic import BaseModel, Field
class ToyCatalog(BaseModel): """Product information from a toy catalog."""
section_name: str = Field( description="The name of the toy section (e.g. Table Toys, Active Toys)." ) product_code: str = Field( description="The unique product code for the toy (e.g., GA457)." ) toy_name: str = Field(description="The name of the toy.") age_range: str = Field( description="The recommended age range for the toy (e.g., 6 +, 4 +).", ) player_range: str = Field( description="The number of players the toy is designed for (e.g., 2, 2-4, 1-6).", ) material: str = Field( description="The primary material(s) the toy is made of (e.g., wood, cardboard).", ) description: str = Field( description="A brief description of the toy and its components and dimensions.", )from llama_cloud_services.extract import ExtractConfig, ExtractMode, ExtractTarget
result = await llama_extract.aextract( data_schema=ToyCatalog, files="Click-BS-Toys-Catalogue-2024.pdf", config=ExtractConfig( extraction_mode=ExtractMode.PREMIUM, extraction_target=ExtractTarget.PER_TABLE_ROW, parse_model="anthropic-sonnet-4.5", ),)Results
Section titled “Results”Again, our schema represents a single toy product, not the entire catalog. The system will return a list[ToyCatalog] with one entry per toy.
You can get
Click-BS-Toys-Catalogue-2024.pdfhere
len(result.data) 153result.data[:10] [{'section_name': 'Table Toys', 'product_code': 'GA457', 'toy_name': 'Dots and Boxes', 'age_range': '6+', 'player_range': '2', 'material': 'wood', 'description': 'base 17x17 cm\n50 border pieces 4x1,2x0,3 cm\n34 trees 2,6x1,4 cm'}, {'section_name': 'Table Toys', 'product_code': 'GA456', 'toy_name': '3 In a Row', 'age_range': '8+', 'player_range': '2', 'material': 'wood, pine, cardboard', 'description': 'base 24x22,5x2,5 cm\n30 cards 5,5x5 cm\n6 chips'}, {'section_name': 'Table Toys', 'product_code': 'GA467', 'toy_name': 'Which Cow am i?', 'age_range': '6+', 'player_range': '2', 'material': 'wood, beech', 'description': '2 cow bases 56x4x4,5 cm\n16 cards 4x5 cm'}, {'section_name': 'Table Toys', 'product_code': 'GA460', 'toy_name': 'Balance Bunnies', 'age_range': '4+', 'player_range': '2', 'material': 'wood', 'description': '1 base 35x12x25 cm\n7 bunnies 7 foxes\n1 dice 3 cm'}, {'section_name': 'Table Toys', 'product_code': 'GA462', 'toy_name': 'Color Combination Race', 'age_range': '4+', 'player_range': '2-4', 'material': 'wood, cardboard', 'description': 'base 6,5x6,5x15 cm, rings 5,5x5,5x0,5 mm\ncardholder 6x6x2 cm, cards 5,5x5,5 cm\ncolor cards Ø 15,5 cm - Ø 7 cm'}, {'section_name': 'Table Toys', 'product_code': 'GA465', 'toy_name': 'Plop It', 'age_range': '6+', 'player_range': '2-4', 'material': 'wood, elastic, cardboard', 'description': 'Catch the right balls and plop them in the net!\n* 2 ploppers 8x5 cm\n* 2 net holders Ø 5cm, length 55 cm\n* 6 cards 1,5x2,5 cm, 30 balls Ø 2,5 cm\n* 1 rope 120 cm'}, {'section_name': 'Table Toys', 'product_code': 'GA466', 'toy_name': 'Whack a Shape', 'age_range': '4+', 'player_range': '2-4', 'material': 'wood', 'description': '* base 38,5x15,5 cm\n* 2 stands 36 half balls, 4 hammers\n* 1 dice 2,5 cm\n* 4 cards'}, {'section_name': 'Table Toys', 'product_code': 'GA458', 'toy_name': 'Sling Puck | Table Hockey', 'age_range': '6+', 'player_range': '2', 'material': 'wood', 'description': '* double sides base 39x21x3 cm\n* 10 chips Ø 2,5 cm\n* 2 pushers 4x4x3 cm'}, {'section_name': 'Table Toys', 'product_code': 'GA039', 'toy_name': 'DIY Birdhouse', 'age_range': '3+', 'player_range': '1', 'material': 'wood', 'description': '* house 9x9x13 cm'}, {'section_name': 'Table Toys', 'product_code': 'GA319', 'toy_name': 'Triangle Domino', 'age_range': '6+', 'player_range': '2-4', 'material': 'wood', 'description': '* 35 triangles 10x10 x10 cm'}]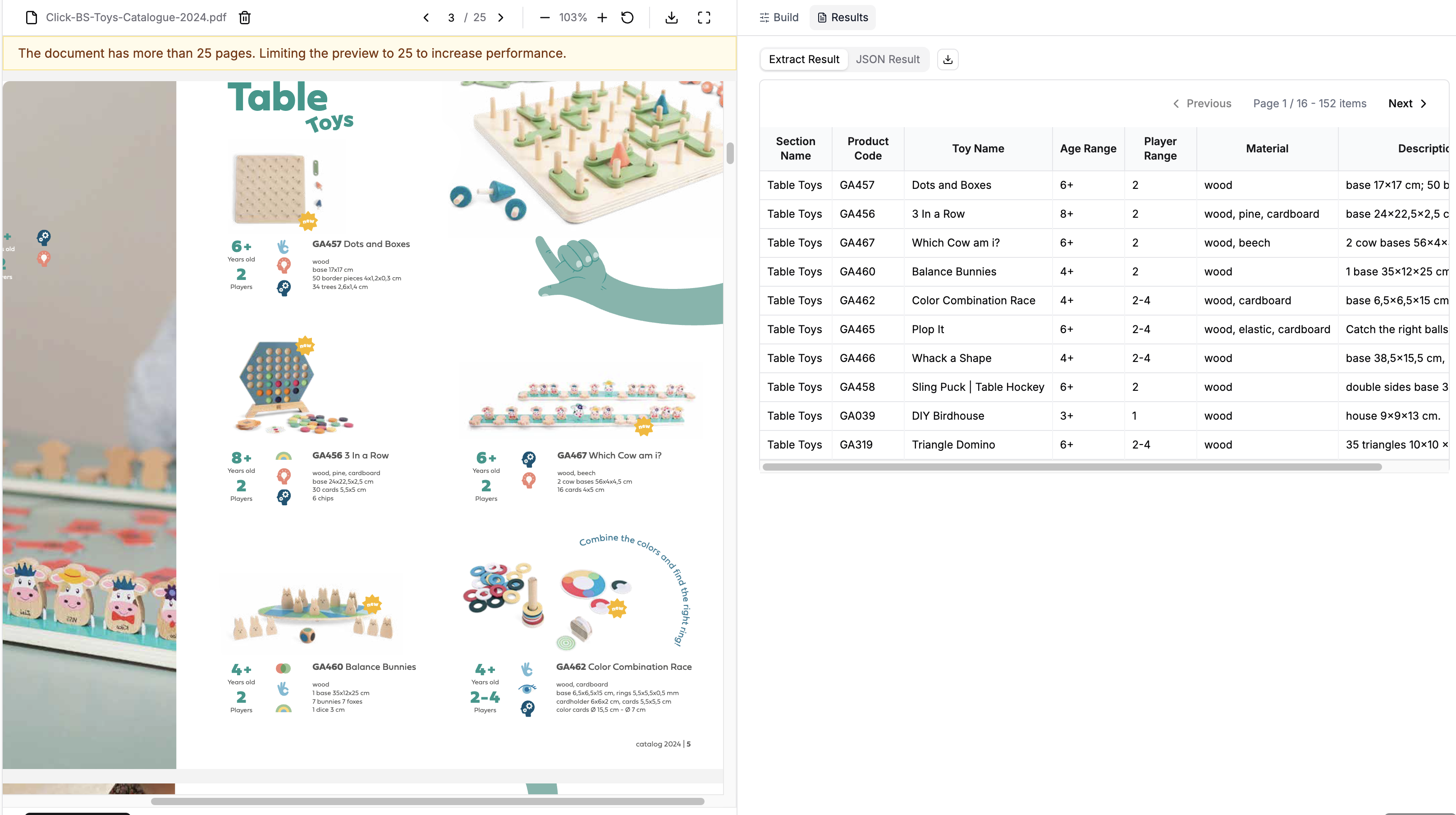
Success! Despite the semi-structured format, we extracted all 152 toy products from the catalog (there’s an extra repeated extracted toy from the Appendix section). LlamaExtract automatically detected the visual patterns separating each toy entry and applied our schema to each one.
Summary
Section titled “Summary”The PER_TABLE_ROW extraction target is powerful for extracting repeating structured entities from documents. Key takeaways:
-
Schema design: Define your schema for a single entity, not the full document. The system returns
list[YourSchema]. -
Works with various formats: Not just traditional tables—any document with distinguishable repeating entities (bullets, numbering, headers, visual separation, etc.). The common requirement is that each entity should contain all the necessary data for your schema within its local context.
-
Automatic pattern detection: LlamaExtract identifies the formatting patterns that distinguish entities and applies your schema to each one.