

Multimodal RAG with VideoDB
RAG: Multimodal Search on Videos and Stream Video Results 📺
Section titled “RAG: Multimodal Search on Videos and Stream Video Results 📺”Constructing a RAG pipeline for text is relatively straightforward, thanks to the tools developed for parsing, indexing, and retrieving text data.
However, adapting RAG models for video content presents a greater challenge. Videos combine visual, auditory, and textual elements, requiring more processing power and sophisticated video pipelines.
VideoDB is a serverless database designed to streamline the storage, search, editing, and streaming of video content. VideoDB offers random access to sequential video data by building indexes and developing interfaces for querying and browsing video content. Learn more at docs.videodb.io.
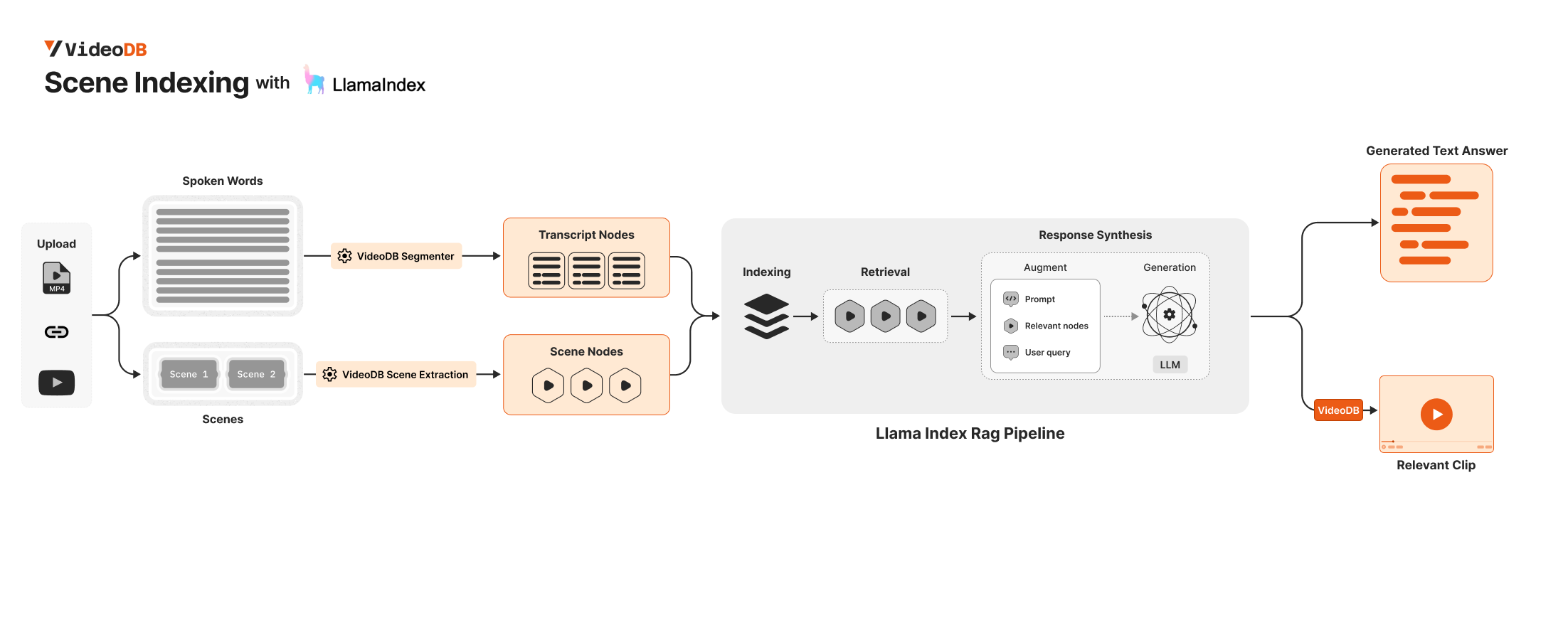
To build a truly Multimodal search for Videos, you need to work with different modalities of a video like Spoken Content, Visual.
In this notebook, we will develop a multimodal RAG for video using VideoDB and Llama-Index ✨.
🛠️️ Setup
Section titled “🛠️️ Setup”🔑 Requirements
Section titled “🔑 Requirements”To connect to VideoDB, simply get the API key and create a connection. This can be done by setting the VIDEO_DB_API_KEY environment variable. You can get it from 👉🏼 VideoDB Console. ( Free for first 50 uploads, No credit card required! )
Get your OPENAI_API_KEY from OpenAI platform for llama_index response synthesizer.
import os
os.environ["VIDEO_DB_API_KEY"] = ""os.environ["OPENAI_API_KEY"] = ""📦 Installing Dependencies
Section titled “📦 Installing Dependencies”To get started, we’ll need to install the following packages:
llama-indexvideodb
%pip install videodb%pip install llama-index🛠 Building Multimodal RAG
Section titled “🛠 Building Multimodal RAG”📋 Step 1: Connect to VideoDB and Upload Video
Section titled “📋 Step 1: Connect to VideoDB and Upload Video”Let’s upload a our video file first.
You can use any public url, Youtube link or local file on your system.
✨ First 50 uploads are free!
from videodb import connect
# connect to VideoDBconn = connect()coll = conn.get_collection()
# upload videos to default collection in VideoDBprint("Uploading Video")video = conn.upload(url="https://www.youtube.com/watch?v=libKVRa01L8")print(f"Video uploaded with ID: {video.id}")
# video = coll.get_video("m-56f55058-62b6-49c4-bbdc-43c0badf4c0b")Uploading VideoVideo uploaded with ID: m-0ccadfc8-bc8c-4183-b83a-543946460e2a
coll = conn.get_collection(): Returns default collection object.coll.get_videos(): Returns list of all the videos in a collections.coll.get_video(video_id): Returns Video object from givenvideo_id.
📸🗣️ Step 2: Extract Scenes from Video
Section titled “📸🗣️ Step 2: Extract Scenes from Video”First, we need to extract scenes from the video and then use vLLM to obtain a description of each scene.
To learn more about Scene Extraction options, explore the following guides:
- Scene Extraction Options Guide delves deeper into the various options available for scene extraction within Scene Index. It covers advanced settings, customization features, and tips for optimizing scene extraction based on different needs and preferences.
from videodb import SceneExtractionType
# Specify Scene Extraction algorithmindex_id = video.index_scenes( extraction_type=SceneExtractionType.time_based, extraction_config={"time": 2, "select_frames": ["first", "last"]}, prompt="Describe the scene in detail",)video.get_scene_index(index_id)
print(f"Scene Extraction successful with ID: {index_id}")Indexing Visual content in Video...Scene Index successful with ID: f3eef7aee2a0ff58✨ Step 3 : Incorporating VideoDB in your existing Llamaindex RAG Pipeline
Section titled “✨ Step 3 : Incorporating VideoDB in your existing Llamaindex RAG Pipeline”To develop a thorough multimodal search for videos, you need to handle different video modalities, including spoken content and visual elements.
You can retrieve all Transcript Nodes and Visual Nodes of a video using VideoDB and then incorporate them into your LlamaIndex pipeline.
🗣 Fetching Transcript Nodes
Section titled “🗣 Fetching Transcript Nodes”You can fetch transcript nodes using Video.get_transcript()
To configure the segmenter, use the segmenter and length arguments.
Possible values for segmenter are:
Segmenter.time: Segments the video based on the specifiedlengthin seconds.Segmenter.word: Segments the video based on the word count specified bylength
from videodb import Segmenterfrom llama_index.core.schema import TextNode
# Fetch all Transcript Nodesnodes_transcript_raw = video.get_transcript( segmenter=Segmenter.time, length=60)
# Convert the raw transcript nodes to TextNode objectsnodes_transcript = [ TextNode( text=node["text"], metadata={key: value for key, value in node.items() if key != "text"}, ) for node in nodes_transcript_raw]📸 Fetching Scene Nodes
Section titled “📸 Fetching Scene Nodes”# Fetch all Scenesscenes = video.get_scene_index(index_id)
# Convert the scenes to TextNode objectsnodes_scenes = [ TextNode( text=node["description"], metadata={ key: value for key, value in node.items() if key != "description" }, ) for node in scenes]🔄 Simple RAG Pipeline with Transcript + Scene Nodes
Section titled “🔄 Simple RAG Pipeline with Transcript + Scene Nodes”We index both our Transcript Nodes and Scene Node
🔍✨ For simplicity, we are using a basic RAG pipeline. However, you can integrate more advanced LlamaIndex RAG pipelines here for better results.
from llama_index.core import VectorStoreIndex
# Index both Transcript and Scene Nodesindex = VectorStoreIndex(nodes_scenes + nodes_transcript)q = index.as_query_engine()The narrator discusses the location of our Solar System within the Milky Way galaxy, emphasizing its position in one of the minor spiral arms known as the Orion Spur. The images provided offer visual representations of the Milky Way's structure, with labels indicating the specific location of the Solar System within the galaxy.️💬️ Viewing the result : Text
Section titled “️💬️ Viewing the result : Text”res = q.query( "Show me where the narrator discusses the formation of the solar system and visualize the milky way galaxy")print(res)🎥 Viewing the result : Video Clip
Section titled “🎥 Viewing the result : Video Clip”Our nodes’ metadata includes start and end fields, which represent the start and end times relative to the beginning of the video.
Using this information from the relevant nodes, we can create Video Clips corresponding to these nodes.
from videodb import play_stream
# Helper function to merge overlapping intervalsdef merge_intervals(intervals): if not intervals: return [] intervals.sort(key=lambda x: x[0]) merged = [intervals[0]] for interval in intervals[1:]: if interval[0] <= merged[-1][1]: merged[-1][1] = max(merged[-1][1], interval[1]) else: merged.append(interval) return merged
# Extract relevant timestamps from the source nodesrelevant_timestamps = [ [node.metadata["start"], node.metadata["end"]] for node in res.source_nodes]
# Create a compilation of all relevant timestampsstream_url = video.generate_stream(merge_intervals(relevant_timestamps))play_stream(stream_url)🏃♂️ Next Steps
Section titled “🏃♂️ Next Steps”In this guide, we built a Simple Multimodal RAG for Videos Using VideoDB, Llamaindex, and OpenAI
You can optimize the pipeline by incorporating more advanced techniques like
- Build a Search on Video Collection
- Optimize Query Transformation
- More methods to combine retrieved nodes from different modalities
- Experiment with Different RAG pipelines like Knowledge Graph
To learn more about Scene Index, explore the following guides:
👨👩👧👦 Support & Community
Section titled “👨👩👧👦 Support & Community”If you have any questions or feedback. Feel free to reach out to us 🙌🏼