

Unit Testing LLMs/RAG With DeepEval
DeepEval provides unit testing for AI agents and LLM-powered applications. It provides a really simple interface for LlamaIndex users to write tests for LLM outputs and helps developers catch breaking changes in production.
DeepEval provides an opinionated framework to measure responses and is completely open-source.
Installation and Setup
Section titled “Installation and Setup”Adding DeepEval is simple and requires 0 setup. To install:
pip install -U deepeval# Optional step: Login to get a nice dashboard for your tests later!deepeval loginOnce installed, you can create a test_rag.py start writing tests.
import pytestfrom deepeval import assert_testfrom deepeval.metrics import AnswerRelevancyMetricfrom deepeval.test_case import LLMTestCase
def test_case(): answer_relevancy_metric = AnswerRelevancyMetric(threshold=0.5) test_case = LLMTestCase( input="What if these shoes don't fit?", # Replace this with the actual output from your LLM application actual_output="We offer a 30-day full refund at no extra costs.", retrieval_context=[ "All customers are eligible for a 30 day full refund at no extra costs." ], ) assert_test(test_case, [answer_relevancy_metric])You can then run tests as such:
deepeval test run test_rag.pyIf you’re logged in, you’ll be able to analyze evaluation results on deepeval’s dashboard:
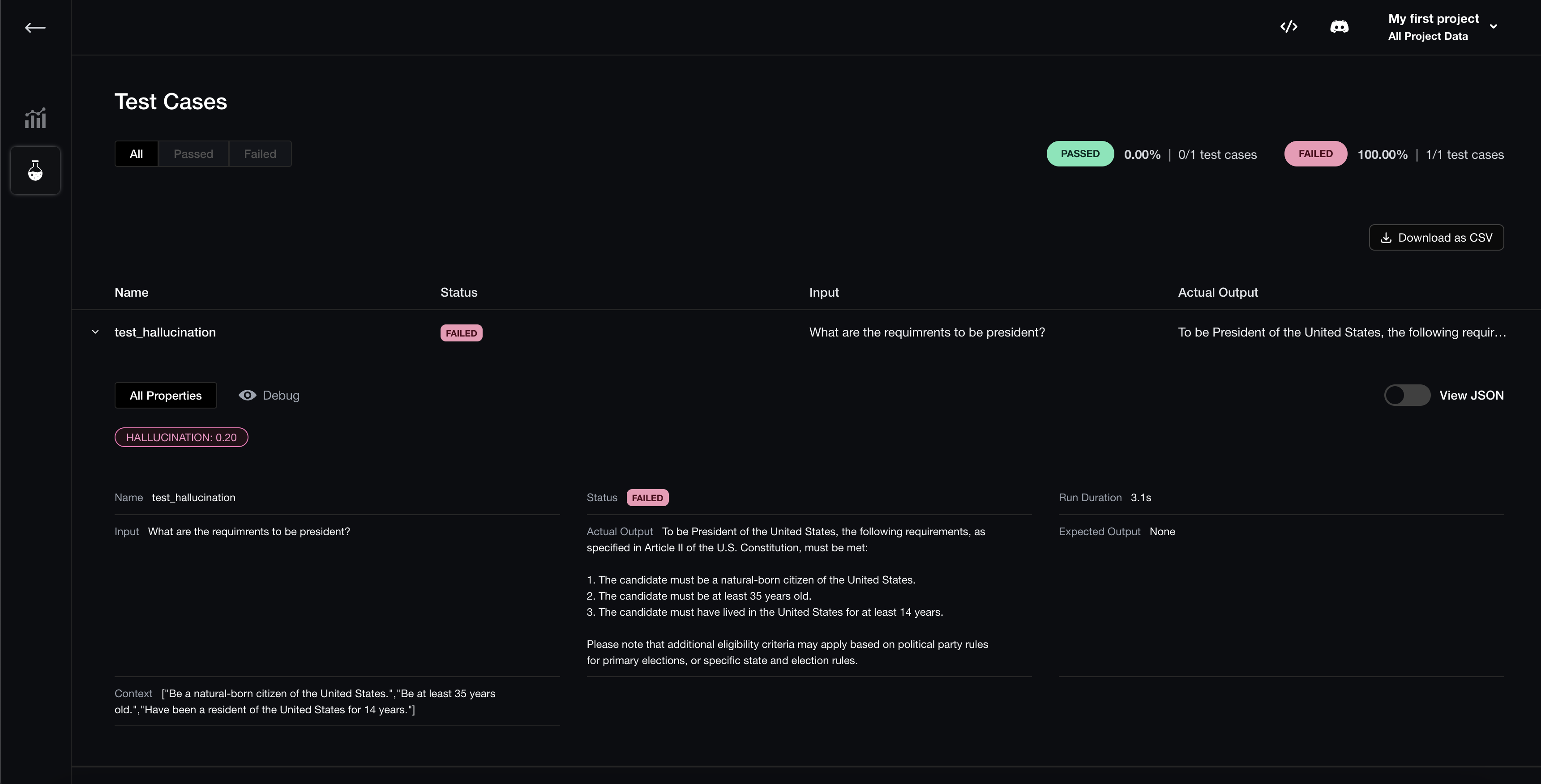
Types of Metrics
Section titled “Types of Metrics”DeepEval presents an opinionated framework for unit testing RAG applications. It breaks down evaluations into test cases, and offers a range of evaluation metrics that you can freely evaluate for each test case, including:
- G-Eval
- Summarization
- Answer Relevancy
- Faithfulness
- Contextual Recall
- Contextual Precision
- Contextual Relevancy
- RAGAS
- Hallucination
- Bias
- Toxicity
DeepEval incorporates the latest research into its evaluation metrics. You can learn more about the full list of metrics and how they are calculated here.
Evaluating RAG for Your LlamaIndex Application
Section titled “Evaluating RAG for Your LlamaIndex Application”DeepEval integrates nicely with LlamaIndex’s BaseEvaluator class. Below is an example usage of DeepEval’s evaluation metrics in the form of a LlamaIndex evaluator.
from llama_index.core import VectorStoreIndex, SimpleDirectoryReaderfrom deepeval.integrations.llama_index import DeepEvalAnswerRelevancyEvaluator
# Read LlamaIndex's quickstart on more detailsdocuments = SimpleDirectoryReader("YOUR_DATA_DIRECTORY").load_data()index = VectorStoreIndex.from_documents(documents)rag_application = index.as_query_engine()
# An example input to your RAG applicationuser_input = "What is LlamaIndex?"
# LlamaIndex returns a response object that contains# both the output string and retrieved nodesresponse_object = rag_application.query(user_input)
evaluator = DeepEvalAnswerRelevancyEvaluator()You can then evaluate as such:
evaluation_result = evaluator.evaluate_response( query=user_input, response=response_object)print(evaluation_result)Full List of Evaluators
Section titled “Full List of Evaluators”Here is how you can import all 6 evaluators from deepeval:
from deepeval.integrations.llama_index import ( DeepEvalAnswerRelevancyEvaluator, DeepEvalFaithfulnessEvaluator, DeepEvalContextualRelevancyEvaluator, DeepEvalSummarizationEvaluator, DeepEvalBiasEvaluator, DeepEvalToxicityEvaluator,)For all evaluator definitions and to understand how it integrates with DeepEval’s testing suite, click here.